
Research
 |
Multimodal misinformation detection serves as a crucial mechanism for safeguarding the authenticity of online content. It aims to identify deceptive or fabricated content by jointly analyzing heterogeneous data modalities, such as text, images, videos, and social context, to assess the veracity of a given news item or post.
|
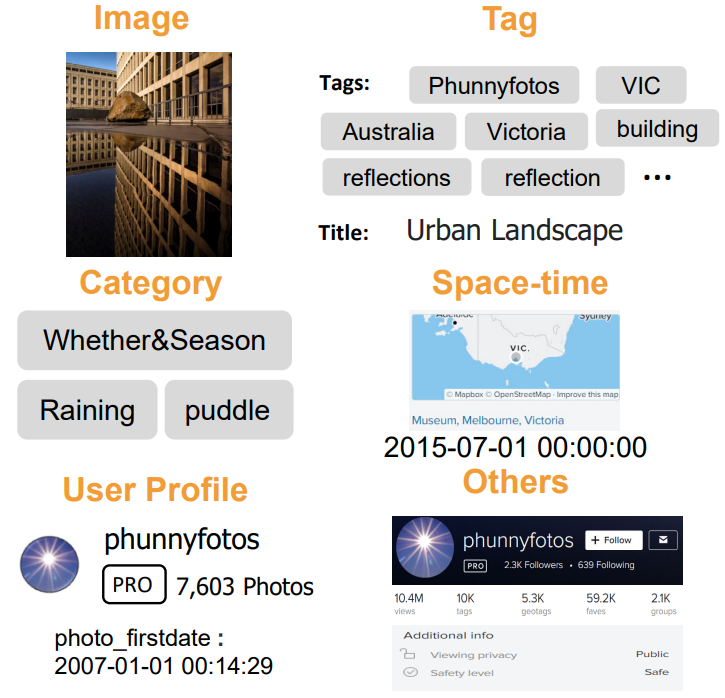 |
Social media popularity prediction is an important channel to explore content sharing and communication on social networks. It aims to capture informative cues by analyzing multi-type data, such as user profile, image, and text, to decide the popularity of a specified post.
|
 |
Image captioning is an exciting research area that lies at the intersection of computer vision and natural language processing. This task aims to automatically generate textual descriptions, i.e., captions, which accurately and naturally describe the content of images.
|
 |
Text-to-image focuses on the generation of photorealistic images from given textual descriptions. It has applications across diverse domains, including the digital art, the educational content creation, and the interactive media.
|
 |
Scene graph generation aims to create the structured representations of visual scenes. It interprets objects within images and categorizes their relationships, transforming a raw visual input into a graph-based format. Such representations can improve AI's grasp of complex scenes and its interaction with the visual world.
|
 |
Visual question answering is to combine computer vision and natural language processing to answer questions based on visual input. It involves interpreting visual content, such as images or videos, and providing accurate answers to textual queries related to the visual elements.
|
 |
Visual dialog aims to answer the current question, given an image, its caption and multi-round Q&A pairs, i.e., dialog history. By engaging in a dialog about visual content, AI systems learn to process and respond to a series of related questions, enhancing their ability to understand complex scenarios and nuances in human queries.
|